Artificial intelligence tools are transforming protein engineering, but industry experts say they can’t do the job alone. The challenge lies in bridging the gap between predicting plausible protein sequences and creating enzymes that actually perform under real manufacturing conditions.
Most AI tools in biology work at the sequence level. Models like those from Evolutionary Scale, ProtT5, and ProGen2 learn statistical patterns from billions of protein sequences. They excel at predicting which mutations appear biologically tolerable. AlphaFold famously predicts three-dimensional structures with remarkable accuracy.
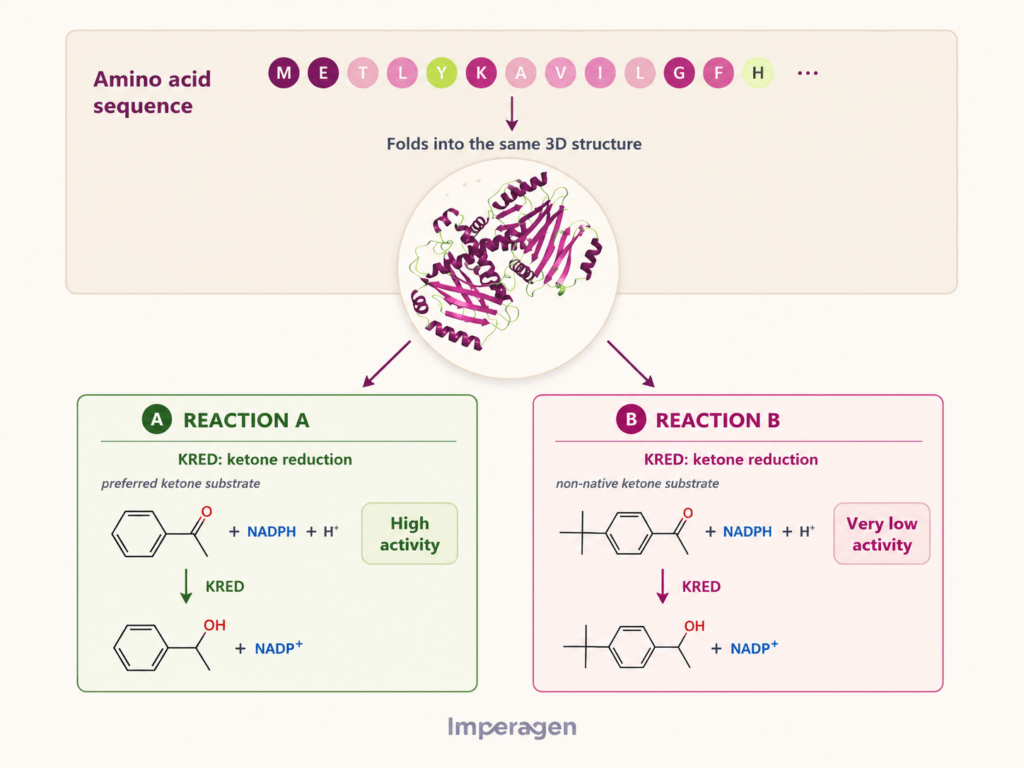
However, knowing a mutation is tolerated doesn’t reveal whether it will make an enzyme faster or more selective under specific conditions. Andrew Currin, Chief Scientific Officer at Imperagen, explains that enzyme engineering requires understanding reaction chemistry at a deeper level.
“The reaction isn’t encoded in sequence data,” Currin notes. Chemistry operates at the quantum mechanical level. Enzymes work by lowering activation barriers and stabilizing transition states. These effects depend on precise atomic arrangements and charge distributions that sequence patterns alone can’t capture.
Physics-based simulation offers a complementary approach. Companies like Imperagen build atomistic models of enzyme-substrate systems and use quantum-mechanical calculations to estimate reaction energetics. This allows screening of millions of mutation combinations anchored to actual reaction chemistry rather than statistical similarity.
The process generates zero-shot predictions before any lab work begins. These predictions identify promising positions for mutation. Experimental results then feed back into the model, creating an iterative learning loop specific to one enzyme and one reaction.
Currin emphasizes that experimental throughput remains essential. His team screens around 2,000 variants per round, generating roughly 1,000 high-quality data points linking sequences to measured activities. This approach takes about four weeks per round.
“A model trained on failures learns just as much as one trained on successes,” Currin explains. Testing only top predictions misses valuable information from variants that underperform.
The debate reflects a broader question about AI’s role in biotechnology. Sequence-level models provide powerful tools for initial screening and structural prediction. Yet catalytic performance under manufacturing conditions requires modeling the chemistry itself.
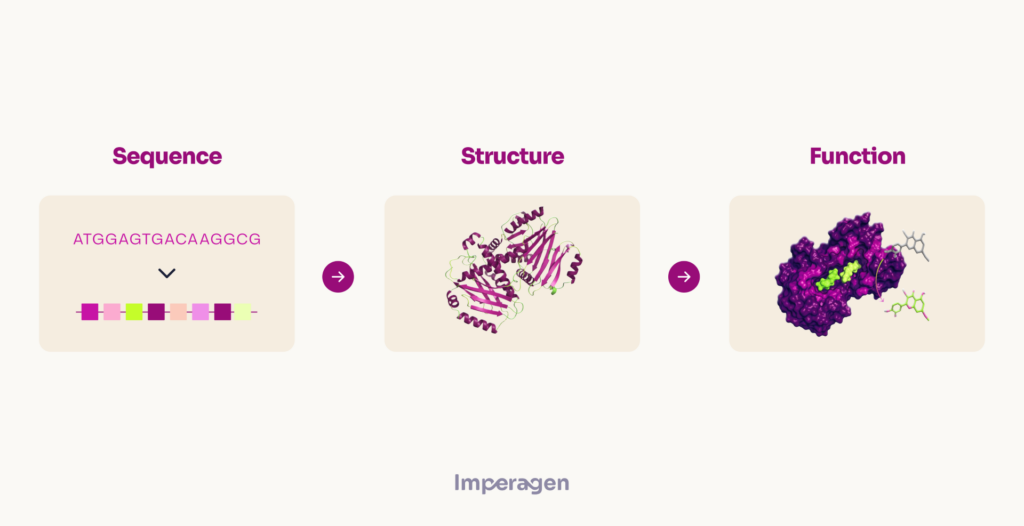
Industry observers suggest the most effective approaches will likely combine both methods. AI excels at navigating vast sequence spaces. Physics-based simulation grounds predictions in reaction mechanisms. Together, they may offer a more reliable path to improved biomanufacturing enzymes.
The post Why AI can’t engineer enzymes alone appeared first on World Bio Market Insights.














